
Корпорация Google представила новую флагманскую ИИ-модель Gemini 2.0 Pro Experimental. Также она сделала «думающую» нейросеть Gemini 2.0 Flash Thinking доступной в приложении Gemini.
Gemini 2.0 Pro Experimental — преемник Gemini 1.5 Pro. Она доступна на платформах Vertex AI, Google AI Studio и подписчикам Advanced в приложении Gemini. Компания подчеркнула хорошие навыки нейросети в программировании и обработке сложных запросов. Она «лучше понимает и обдумывает знания о мире».
Контекстное окно профессиональной версии составляет 2 млн токенов. Она способна за раз понять все семь книг о Гарри Поттере, оставив в запасе около 400 000 слов.
Gemini 2.0 Flash обзавелась наиболее экономичной и оптимизированной версией Lite.
Производительность серии Gemini 2.0 демонстрирует значительный прирост по сравнению с 1.5 в ряде бенчмарков.
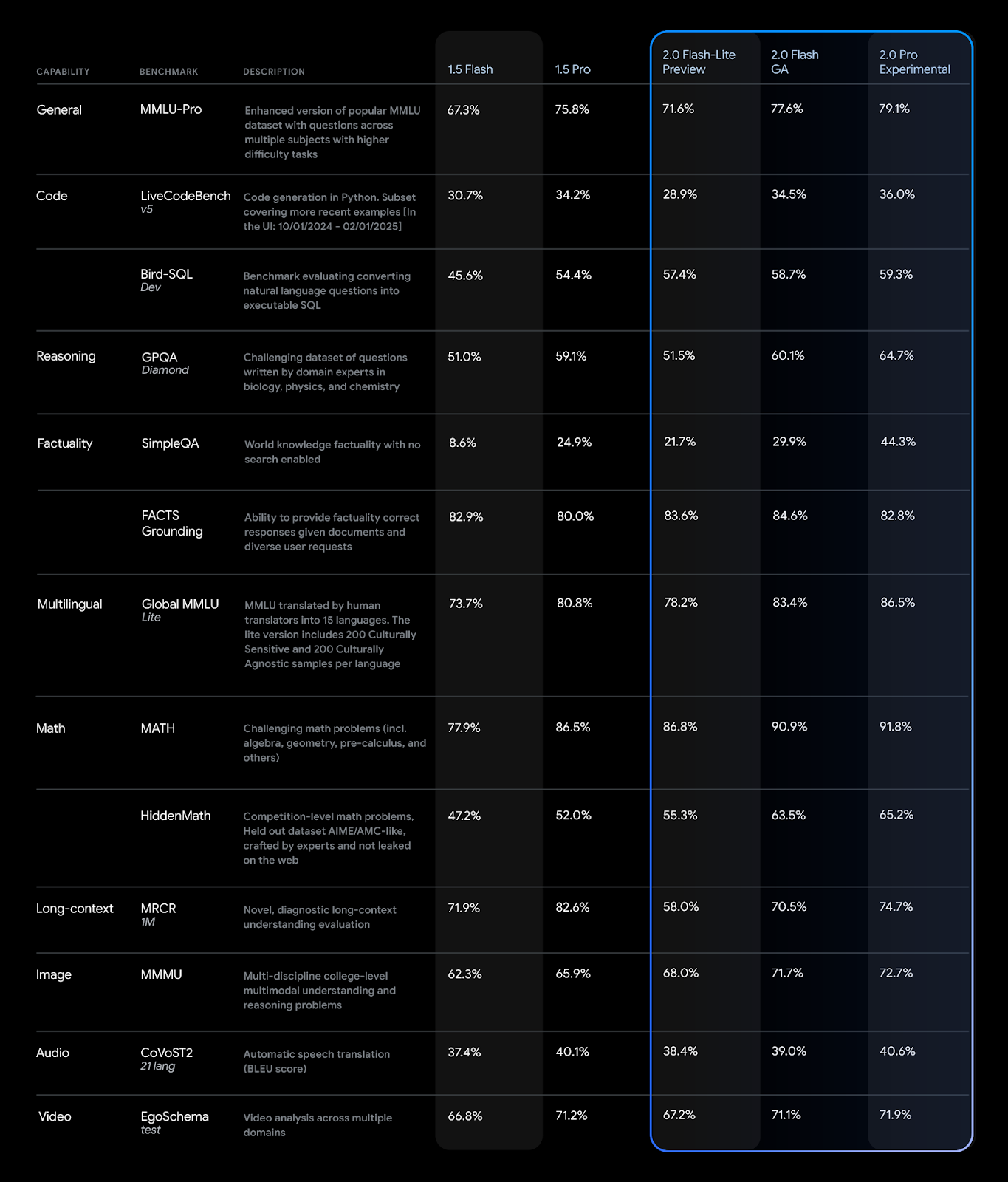
Компания уменьшила стоимость вывода для Flash и Flash-Lite, установив ее ниже, чем у Gemini 1.5 Flash, при этом повысив производительность.

Хайп вокруг дешевой и эффективной китайской ИИ-модели DeepSeek-R1 вызвал вопросы касательно целесообразности миллиардных трат на искусственный интеллект. Началась гонка за удешевление нейросетей.
Рассуждающая ИИ-модель за $50
В январе компания NovaSky представила думающую ИИ-модель с открытым исходным кодом Sky-T1, обучение которой обошлось всего в $450.
Исследователи из Стэнфорда и Университета Вашингтона пошли дальше и смогли обучить рассуждающий ИИ за менее чем $50. Модель s1 демонстрирует схожие с o1 от OpenAI и R1 от DeepSeek результаты в тестах. Она доступна на GitHub вместе с данными и кодом, который применялся для обучения.
Команда проекта взяла за основу готовую базовую нейросеть и доработала с помощью дистилляции — процесса, при котором из другой ИИ-модели извлекаются способности к «рассуждению» путем обучения на ее ответах.
В основе s1 лежит небольшая бесплатная ИИ-модель Qwen от Alibaba. Исследователи создали набор данных, состоящий из 1000 тщательно подобранных вопросов и ответов на них из Gemini 2.0 Flash Thinking Experimental.
Обучение с применением 16 графических процессоров Nvidia H100 заняло менее 30 минут.
Дистилляция этична?
Идея запуска передовых ИИ-моделей без миллионных вложений может показаться захватывающей. Однако крупные лаборатории, вероятно, недовольны таким подходом.
OpenAI обвинила DeepSeek в неправомерном сборе данных из своего API для дистилляции.
Разработчики s1 стремились найти простейший способ достичь высокой производительности. Для обучения применили подход Supervised Fine-Tuning (SFT), в рамках которого модели дается указание подражать определенному поведению в наборе данных.
SFT дешевле крупномасштабного обучения с подкреплением.
Google предлагает бесплатный доступ к Gemini 2.0 Flash Thinking Experimental на платформе Google AI Studio.
Крупные инвестиции нужны
Несмотря на высокий ажиотаж вокруг дешевых нейросетей, техгиганты не спешат снижать объем инвестиций в обучение новых моделей.
Meta, Google и Microsoft намерены сохранить миллиардные вливания в ИИ-инфраструктуру.
Дистилляция показала себя как хороший метод доработки моделей, но она не создает новые нейросети, которые способны значительно превзойти доступные сегодня решения.